

Technical
Text mining relational data
-
Technical documentation: Database Structure

The relational database for storing the text mining data contains a database schema for each of the project languages. The following schema are available in each TM database: bg, de, el, en, pl, and ro. The examples below focus on the English schema (en); the schema for any of the other languages are identical. Each shema is split into two group of tables:
Document related
The "doc", "sent" and "para" tables contain infromation about the whole documents, paragraphs in the documents and sentences in each paragraph. The diagram below depicts the columns and relations between the three tables.
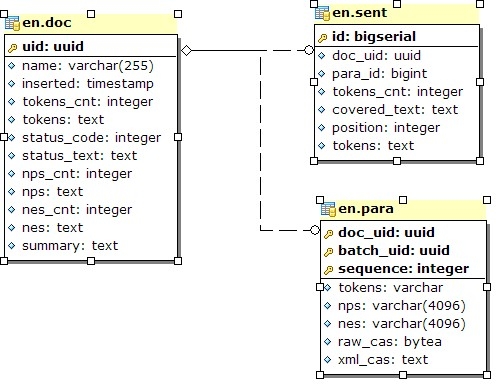
Each document, paragraph and sentence contains text fields for the tokens, noun phrases and named entities contained in the corresponding entity. These text fields enlist the corresponding annotaions as a comma-separated list of numbers.
Annotation related
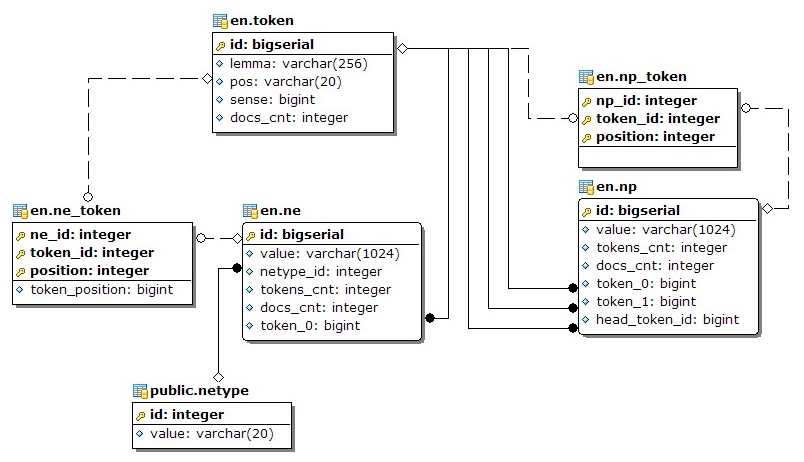
The other tables in the language schema are used for storing the unique text minnig annotations. The follwoing annotations are stored:
- tokens - tokens are the first annotations stored for a given document because the other annotations consist of tokens. Two tokens are assumed to be equal if their lemmas, PoS tags and word senses are equal.
-
noun phrases - two noun phrases are assumed equal if they consist of one and the same list of tokens. The "noise" words are removed prior to comparing two NPs. For examaple, the phrases "the blue sky" and "a blue sky" are equal, because the determiners "a" and "the" are ommited. The table "np" contains three fields, related to the tokens:
- head_token_id - this field indicates the head noun of the noun phrase;
- token_0 - this field indicates the first token in the structure of the noun phrase;
- token_1 - this field indicates the second token in the structure of the noun phrase;
- the rest of the tokens in the structure of the noun phrase are stored in the "np_token" table. This separation between the first two tokens and the rest drastically improves the performance of the queries.
- named entities - being noun phrases, two named enitites are considered equal if they both consist of one and the same list of tokens. Similar to the NPs, the "ne" table contains a field "token_0", designated for the first token in the NE. The rest of the tokens contained in the named entity are stored in "ne_token" table. Additionally, the "ne" table has a foreign key to the "public.netype" tables, where the different named entity types are stored.
The diagram below shows the columns and the relations between the annotaion-related database tables.
; return false;") |
; return false;") |
ATLAS (Applied Technology for Language-Aided CMS) is a project funded by the European Commission under the CIP ICT Policy Support Programme.